In this excellent summary paper ‘Did Google and Facebook kill the media revenue model?‘ Frederic Filloux takes a deep insight on the evolution of media advertising evolution in last decades. It benefitted initially paper media and it got completely upended by Internet. The interesting part is that its actual value has also plummeted – making it cheaper for people to advertise but also diminishing the possible revenue stream for media.
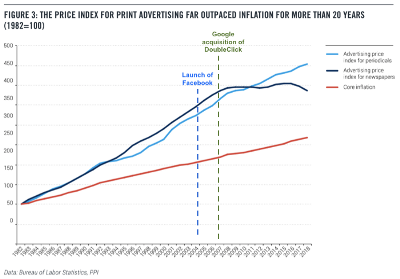
“The inefficiency of advertising in print, radio, and TV has always been its historical flaw.” By providing a far more targeted solution, internet advertising suddenly increased dramatically advertising efficiency. In addition, it was suddenly possible to much better measure the effectiveness of a campaign to improve it.
In addition, availability of advertising channels created a major deflation of advertising expenditure and the post contains staggering graphs (out of which the illustration of the post is extracted) showing how total advertising value plummeted in the last decade, with total media adverting expenditure diminishing by more than 25% in most developed countries (after an historical increase that was much more than inflation, so it is also sort of a correction).
Could printed media have reacted earlier? Maybe, but as Frederic Filloux concludes, the changes were so systemic and overwhelming that some exceptions may have transformed sufficiently, but certainly not the entire industry. “Most of the legacy media were in denial. They acted too late and too little. But they were not in a position to do otherwise.”
At the end, media advertising is another area where internet has upended the value chain, and at the same provided more value to advertisers. It should be seen as a quite positive shift for the overall value chain and consumers, were it not for the overwhelming position of Google and Facebook.